
输入的坏数据等于输出的坏数据。这句众所周知的短语在光伏电站的技术设计和发电量模拟非常重要。大多数太阳能公司和技术人员都明白这一点,并且正在仔细评估用于可行性的太阳能资源数据的不确定性。
除了质量和准确性外,查看输入太阳能和天气数据的原始时间粒度也很重要。在这些方面,我们目前两种主要方法:
- 使用人工每小时数据配置文件,由合成生成的月平均值生成。
- 使用真实的每小时数据时间序列,作为天气数据模型的输出。
尽管使用人工生成的小时值是一种常见的做法,但不建议采用这种方法。
在本文中,我们将讨论使用实际每小时或次每小时时间序列而不是从月平均值合成生成的小时数据的好处。
为此,我们使用从Solargis模型获得的真实数据以每小时分辨率运行光伏模拟。然后,我们使用合成生成的每小时数据(来自原始每小时时间序列的月平均值)将结果与相同的模拟进行比较。
一 、更低的不确定性,更大的P90值
光伏发电输出模拟所需的主要太阳能和天气参数是入射太阳辐射和光伏电池温度(根据空气温度计算得出)。
为了进行可靠的发电量模拟,在每个时间步长的太阳辐射和温度之间进行正确的匹配非常重要。否则,电厂的输出和相关能源损失可能会被高估或低估。
在使用合成数据时,应将这种影响作为不确定性分析的附加因素。
分析案例:
位于西班牙东南部的 15 kWp 系统的 PVsyst 软件示例模拟中,我们看到使用实际每小时数据与使用合成生成的每小时数据相比,年发电量差异为 1.2%。对其它地点的类似测算显示出更高的差异,但大多在±2%以内,这可以被认为是使用合成生成的数据时对额外不确定性的合理估计。对于太阳辐射和温度模式更复杂的地点,预计额外的不确定性会更高。
一旦考虑了所有不确定性,我们可以比较下表1中示例站点的光伏能量模拟结果。
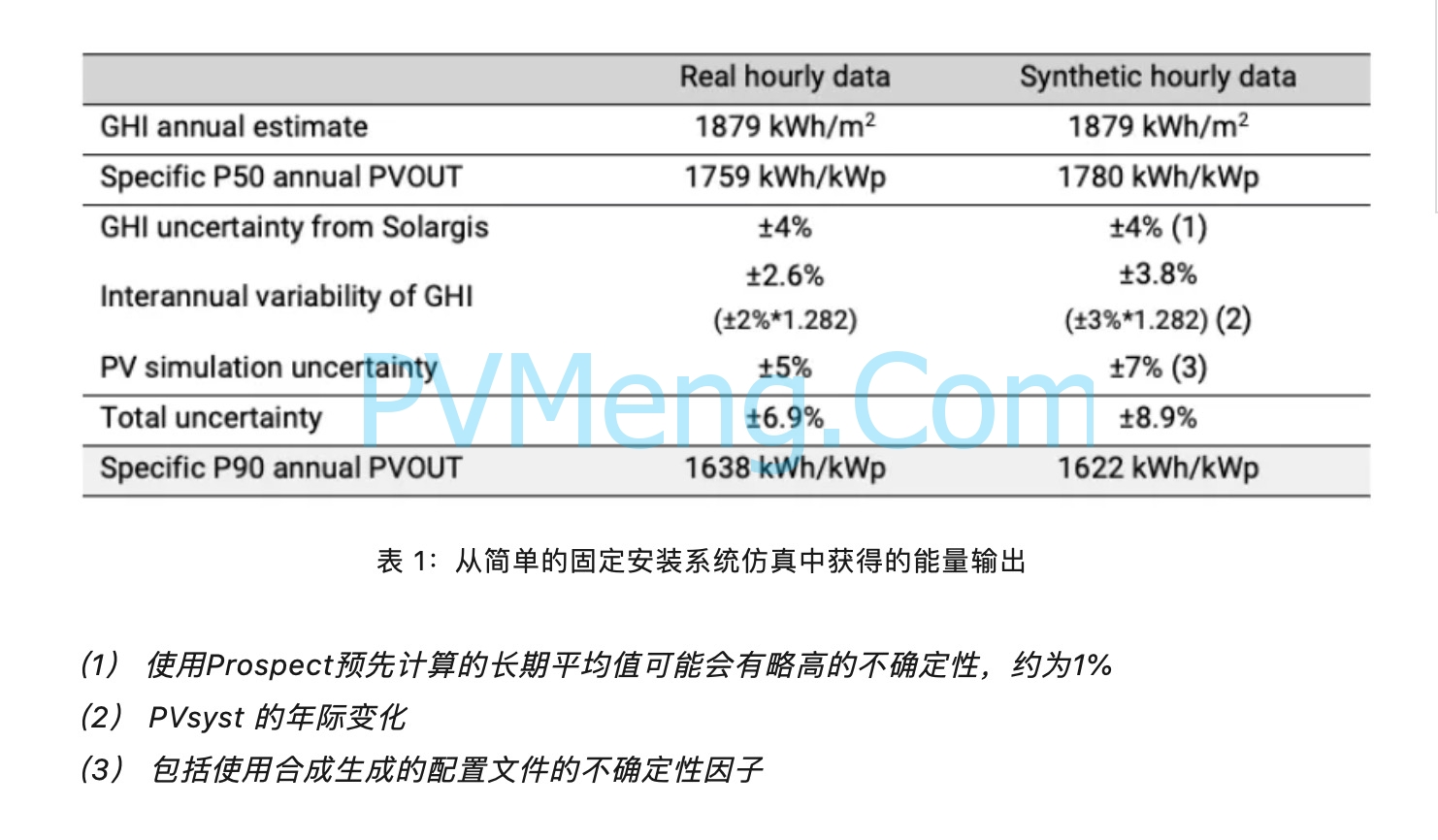

在上面的例子中,即使使用合成的每小时数据时,P50值更高(乍一看看起来更“吸引人”),但具有较高不确定性的事实会导致较低的P90值(最终“吸引力”较低)。这种情况在下面的概率图中进行了说明。无论如何,为了项目的成功,建议始终使用不确定性最小的方法。
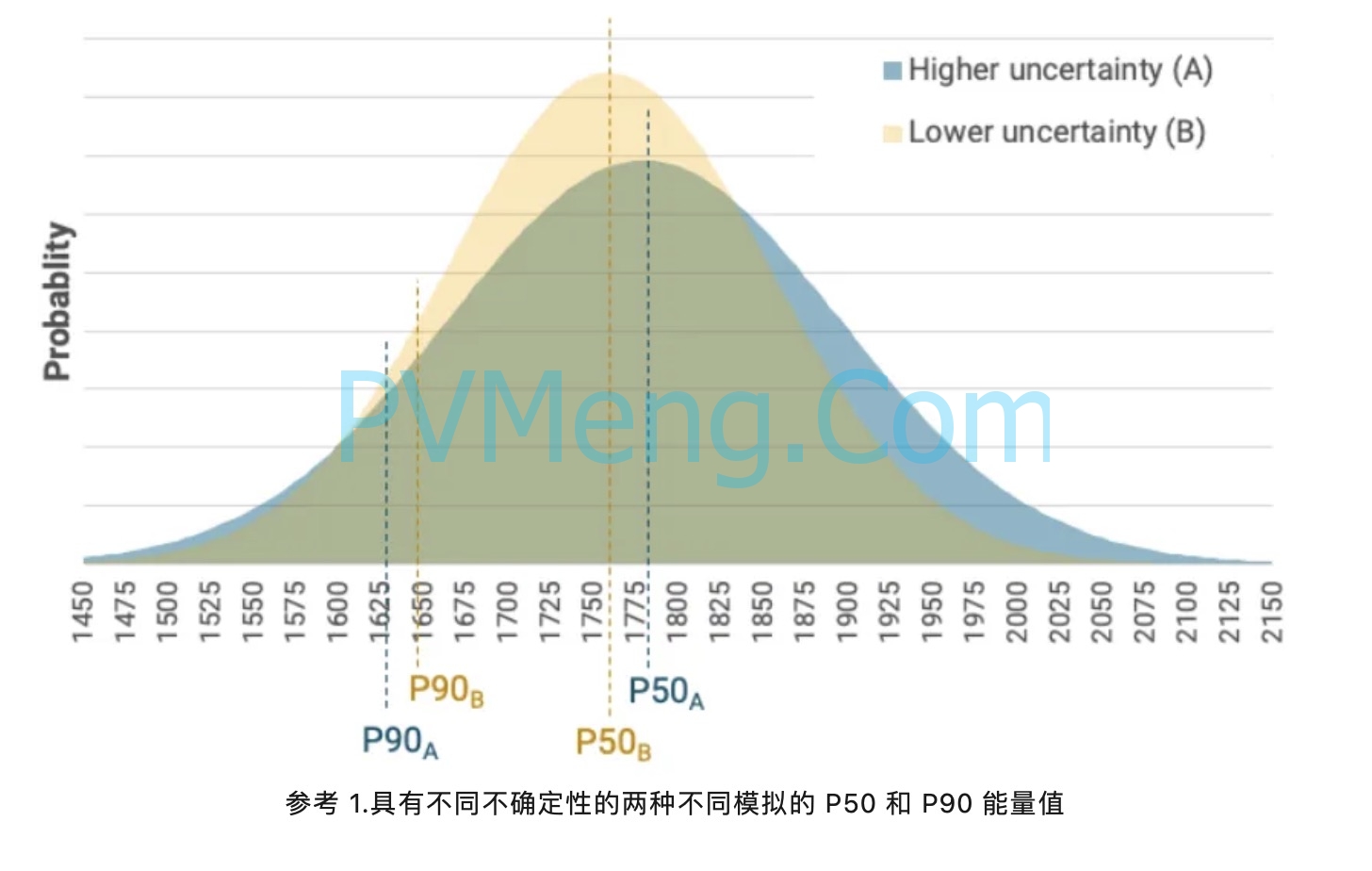
二、能够准确估计年际变率
为了准确测算年度发电量的总不确定性,我们需要知道天气条件和预期发电量的年度变化。如果我们从最近的历史中知道至少 10 年的年度总和,则可以准确估计这一点。在没有多年时间序列的情况下,我们只能猜测年度发电量的预期年度变化,但这是非常困难的,因为逐年变化具有非常复杂的地理特征。
在没有时间序列数据的情况下,替代方法是利用具有相似辐照水平和气候条件的地点的GHI年变率值。例如,在 PVsyst 软件中计算 P90 时,默认使用此方法。这种方法有两个问题。首先,在具有相似气候条件和太阳辐射的不同地点,年变化可能会有很大差异。其次,正如在之前的博客文章中所解释的,GHI的年度变化性并不等于光伏输出的年度变化性。

三、无法了解天气数据的范围和极端情况,以实现最佳光伏设计
尽管真实数据和合成数据的月度总和相同,但逐小时分析将始终显示关键差异。这意味着在合成生成的每小时时间序列中,典型值和极值没有被完全捕获,合成数据通常显示系统偏差。在使用合成数据时,在不对预期天气条件做出更高风险假设的情况下选择最佳设计和组件成为一项不可能完成的任务。
对于本文中使用的样本站点,在比较两个数据集时,可以直接观察到这种差异,即实际每小时 TMY 和合成生成的年份。数据中记录的最大值之间存在差异,但高于或低于特定阈值的每小时值的统计出现也存在差异。对于仿真中用作输入的所有参数,可以很容易地观察到这一点;在我们的例子中,全球水平辐照 (GHI)、漫反射水平辐照 (DIF)、气温 (TEMP) 和风速 (WS)。样本站点的相关统计数据如表3所示。
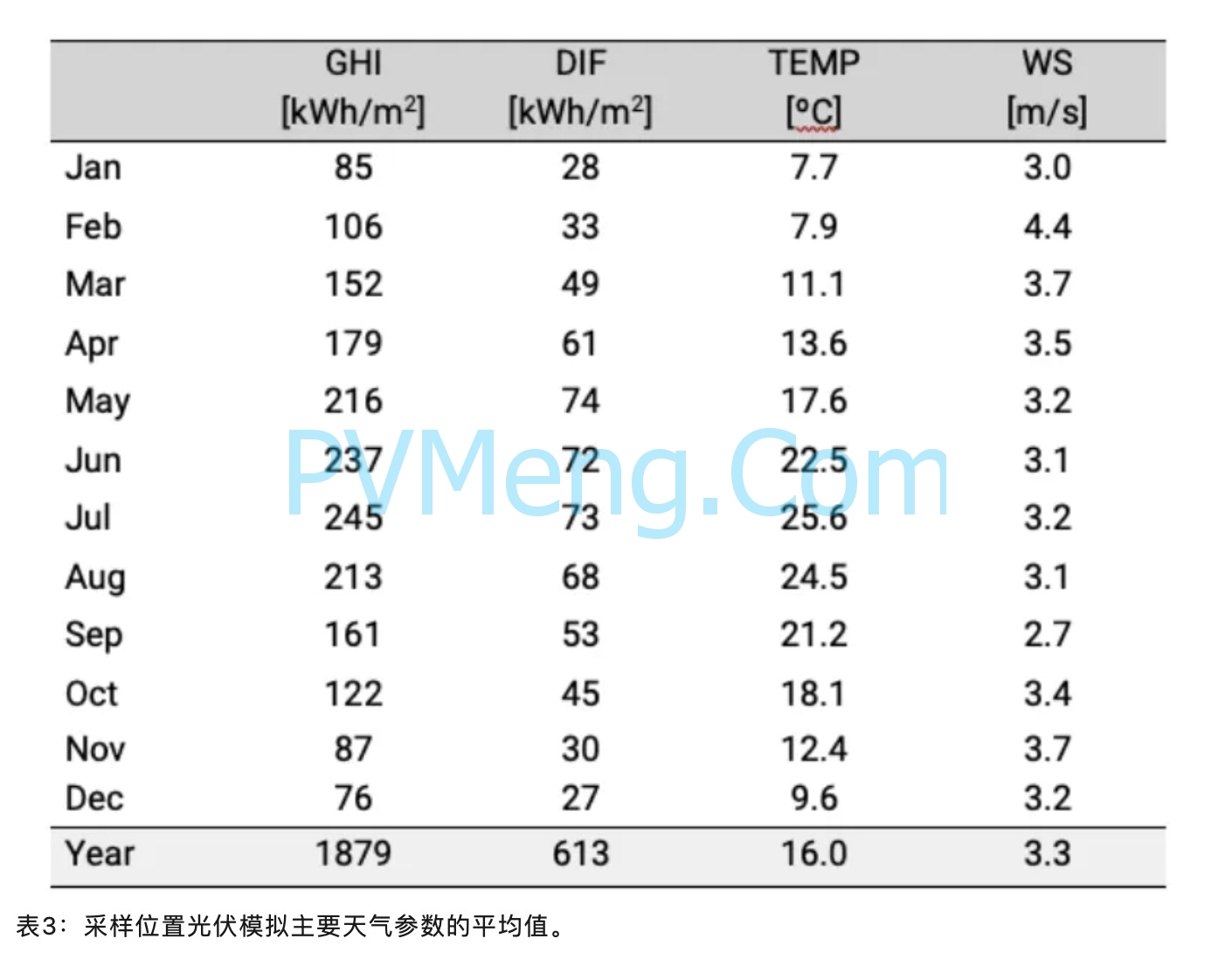
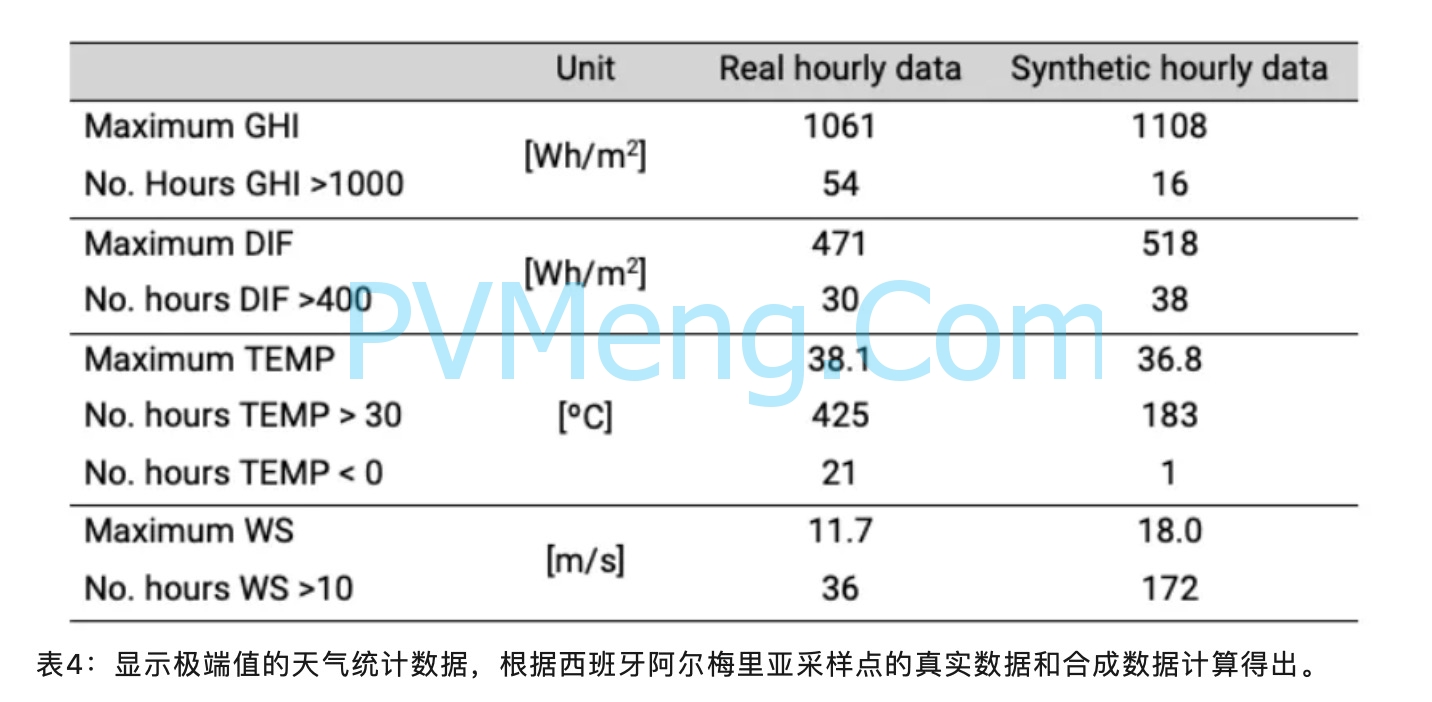
因此我们建议设计人员,为了获得更完整的结果,建议使用一套完整的历史时间序列数据而不是又多年月平均数据拆算而来的小时数据。
四、无法准确的进行收入规划和自我消费分析
每小时分布通常不能很好地反映在合成数据中,这可能会对预期收入的分析产生重大影响。这不仅是因为发电价格的差异,可能是根据现货市场或最终购电协议(PPA)设定的小时价格,还因为光伏系统是为自发自用而设计的。在这种情况下,还需要对发电曲线进行准确的长期预测,以便设计一个最大限度地提高光伏系统产生的能量的计划。
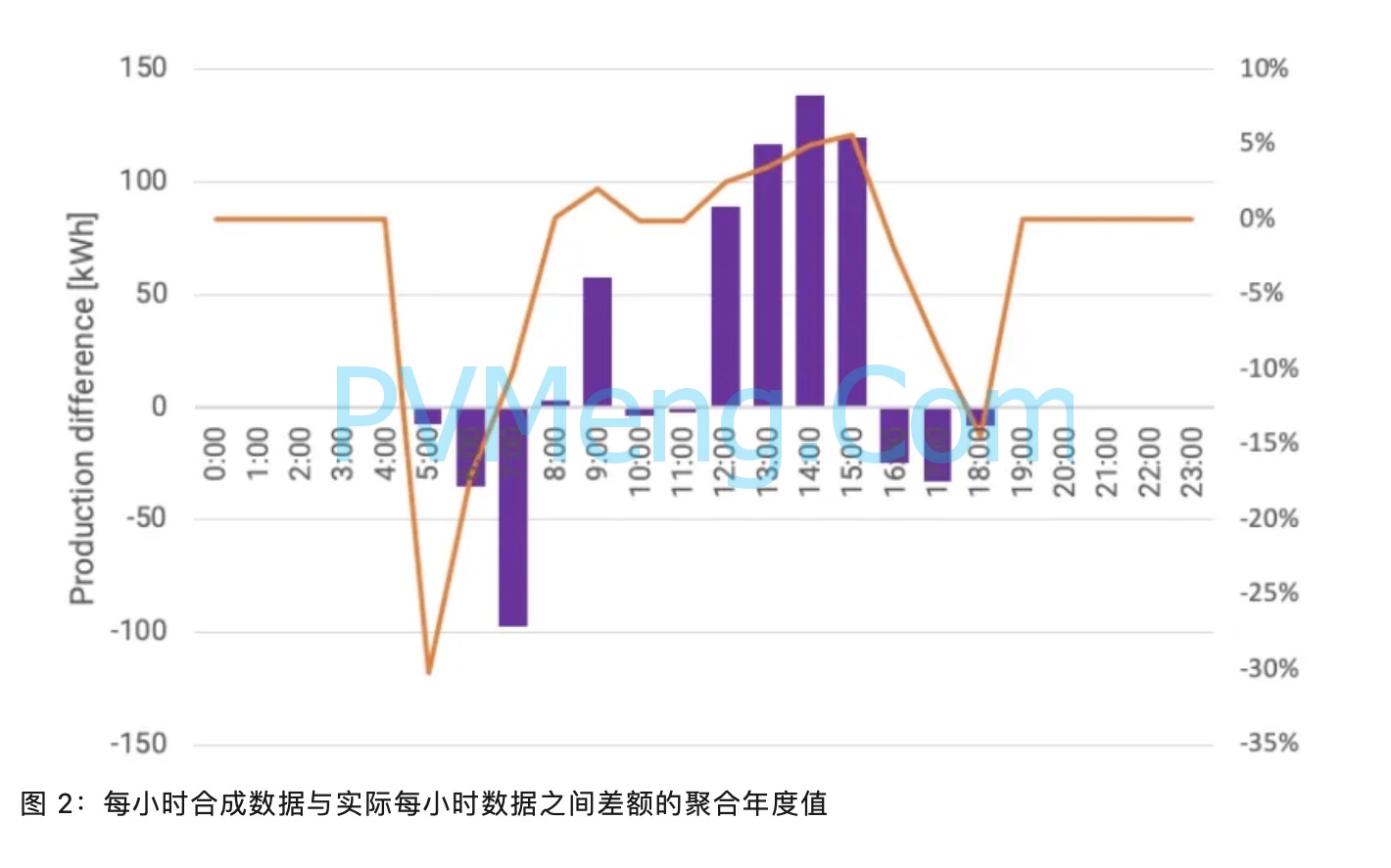
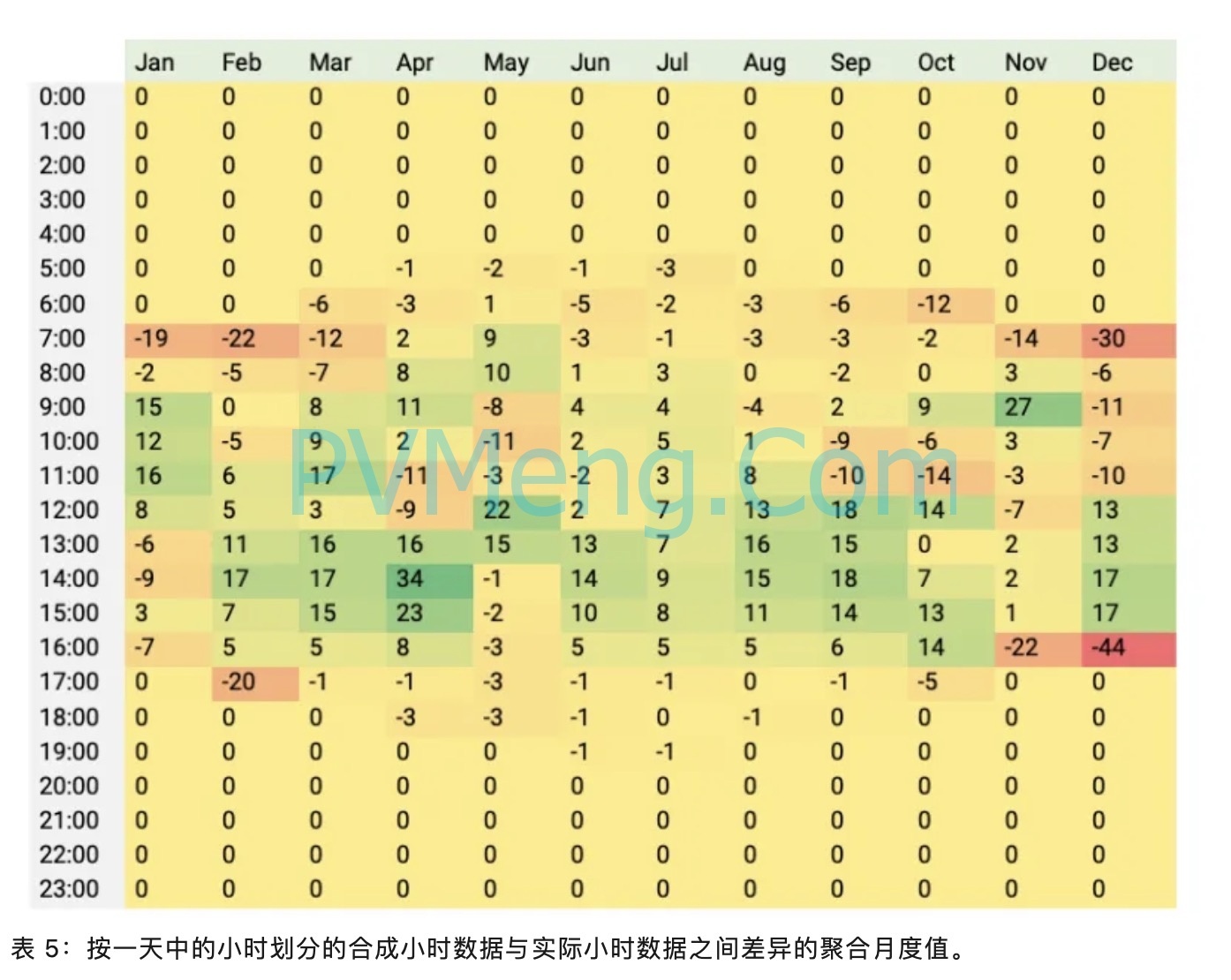
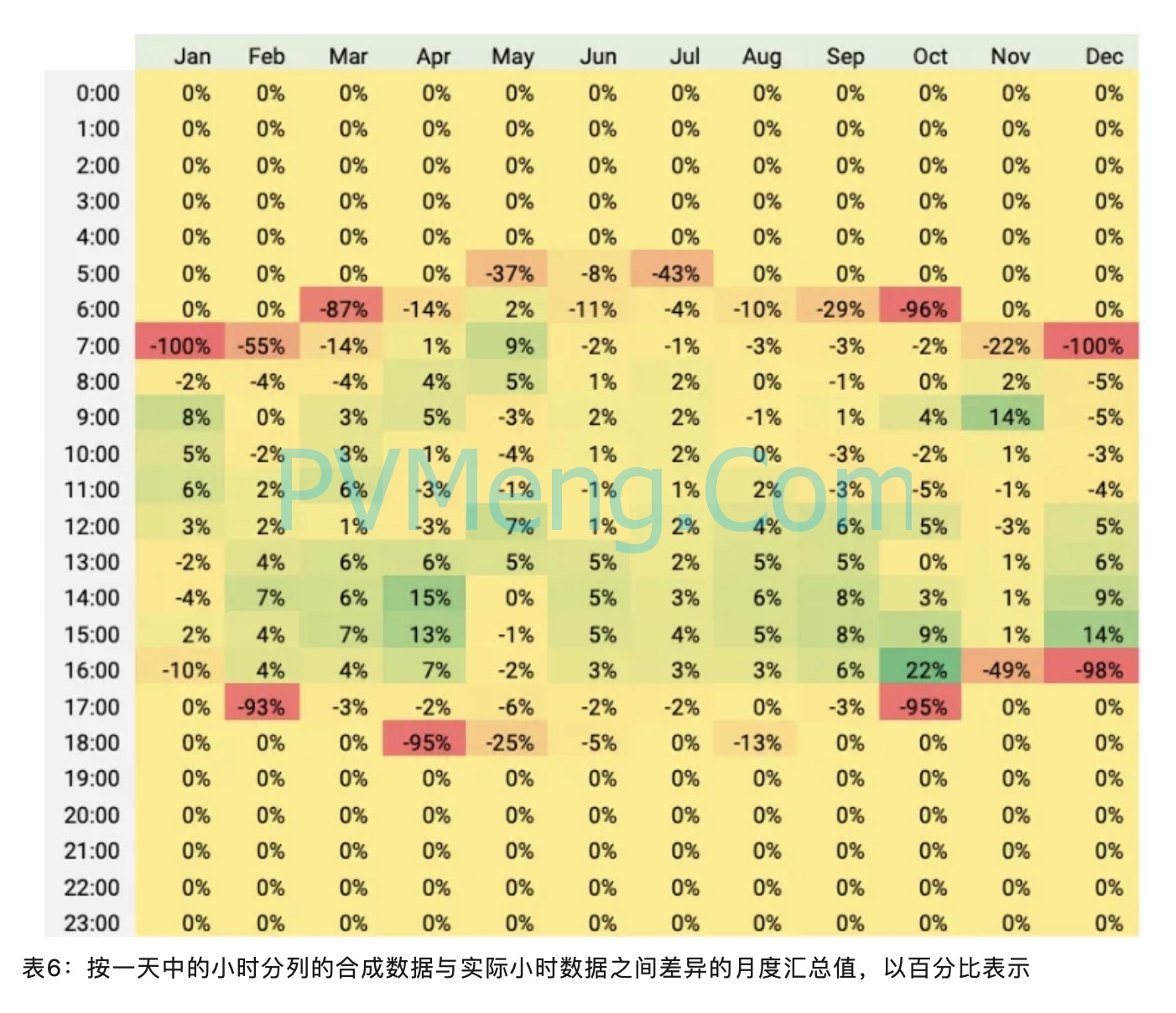
图 2 以及下面的表 5 和表 6 表示将基于时间序列的模拟与真实和合成的每小时数据进行比较时每小时的差异。在年度水平上,在综合数据中看到的最高高估发生在下午。从月度偏差表中,我们还可以看到,一天中第一个小时和最后一个小时的明显差异是显着的,尤其是在某些月份。
五、无法使用高质量的地面测量来验证(并提高精度)模型数据
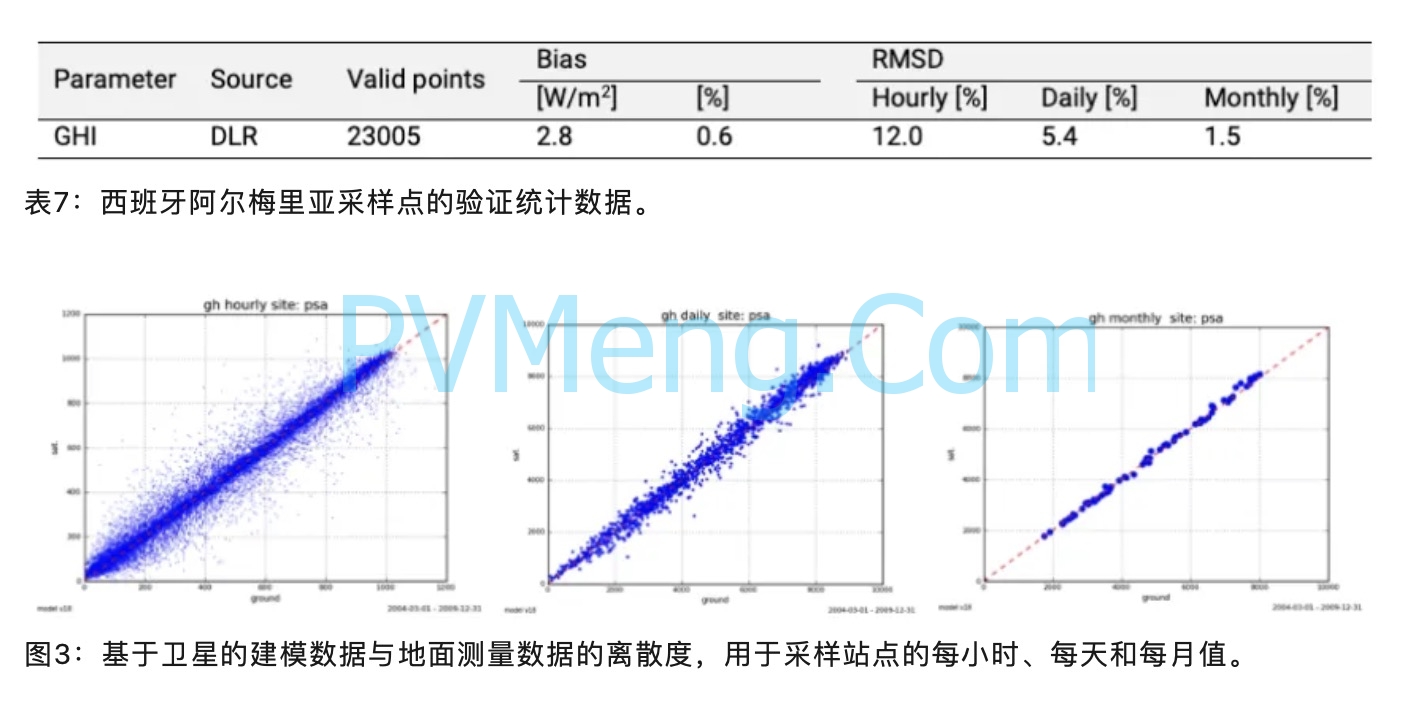
基于卫星的太阳能资源模型在给定地点的性能可以用一组指标来表征。偏差或平均偏差 (MBD) 表征给定站点的系统模型偏差,即系统性高估或低估;均方根偏差 (RMSD) 和平均绝对偏差 (MAD) 用于指示瞬时值的误差分布。
从项目现场获得高质量的地面测量数据为计算此类统计数据和验证天气数据模型提供了独特的机会(表7和图3)。但是,只有当我们在实际值的每小时粒度中有一个重合的周期时,我们才能进行适当的比较并确定模型的可能偏差。合成生成的数据或月平均值不适合验证太阳能资源模型,因为它们不代表实际测量值。
验证模拟中使用的天气数据的质量将为结果提供可信度。但是,如果记录了足够的时间(至少 12 个月),它也可以用于模型位点适应和数据关联。然后,使用现场自适应模型以更高的精度和更低的不确定性重新计算数据集。
六、无法在整个项目生命周期内计算一致的指标
天气数据模型能够提供历史时间的真实每小时数据,但这些模型还提供了在整个光伏电站生命周期内进行实时数据计算的可能性(见图5)。这意味着,用于电厂现场勘探、规划和设计的相同数据源,在以后的阶段也可以在电厂运行期间使用。这样可以将实际绩效评估与项目开发期间最初计算的绩效评估进行比较。当电厂成为重新评估的对象时,它变得很有帮助,允许更透明的交易和对与太阳能光伏资产相关的投资进行可靠的评估。

总结
使用从月平均值合成生成的数据是一种过时的方法,因为它允许的分析范围非常有限,并且从模拟中获得的结果具有更高的不确定性。因此,使用合成生成的数据可能会导致错误的决策。在所有情况下,最好使用来自可靠来源的真实每小时数据:以获得最准确的结果,并对光伏电站进行完整的分析和优化。使用月平均值对于项目初步阶段的现场勘探和非常基础的研究很有用。

本文来自小麦爱光伏,本文观点不代表光动百科|PVMeng.com立场,转载请联系原作者,原文链接https://mp.weixin.qq.com/s/NwSA_so6tG9DUYKYs3Nopg 。
